Better Decisions. Better Outcomes.
Helping Lenders
Find Better Borrowers™
Trust Science's explainable AI surfaces the Invisible Primes™ that traditional scores miss — turning complex data from every source into clear, confident lending decisions.
Actual results experienced by auto lenders using T°Score™
Trusted by leading lenders across North America














The full credit picture.
No blind spots.
Access traditional, alternative, and proprietary credit data in a single, unified platform — purpose-built for modern lenders who can't afford blind spots.
- Real-time bureau pulls with instant fraud detection
- Traditional, alternative, and proprietary data layered on every file
- 360° view of borrower profiles
- FCRA-Compliant Insights From Lead to Loan™

Score deeper.
Approve more.
Using our patented scoring technology, T°Score™ integrates conventional credit data with unique alternative signals to provide a comprehensive and evolving assessment of each applicant — identifying the Invisible Primes™ that traditional methods frequently overlook.
- Patented AI model combining 100+ data signals
- Identifies creditworthy Invisible Prime™ borrowers
- Surfaces hidden subprimes that appear creditworthy on paper — before they reach your portfolio
- Explainable scores with clear adverse action reasons
- Models that sharpen continuously as real loan outcomes feed back in

See the full income picture.
Lend with confidence.
CashFlow+™ delivers accurate, actionable insights into income patterns, cash flow reliability, and financial behavior — giving lenders the full picture before a single dollar is committed.
- Bank transaction data analysis across thousands of institutions
- Income verification for gig workers and non-traditional earners
- Reveals income consistency and emerging repayment risk signals
- Works standalone or amplifies Credit Bureau+™ and T°Score™ for a complete view

in 5
Creditworthy borrowers
invisible to traditional scores
Over 90 million people in North America lack a fully recognized credit footprint — not because they're risky, but because the system can't see them. Trust Science can.
Find Invisible Primes™Limited or no credit history
Individuals with limited interaction with conventional credit products — invisible to standard scoring models despite responsible financial behavior.
Recent immigrants
Creditworthy people whose prior financial history is not recognized by domestic credit systems despite years of responsible behavior abroad.
Underserved communities
Populations affected by systemic barriers that reduce access to fair and inclusive financial services — despite being fully capable of repayment.
Gig workers & non-traditional earners
Consumers with irregular income streams or alternative employment structures that traditional underwriting models simply weren't built to handle.
More than a platform.
A strategic lending partner.
Trust Science delivers end-to-end services that transform how lenders acquire customers, manage risk, and navigate securitization.
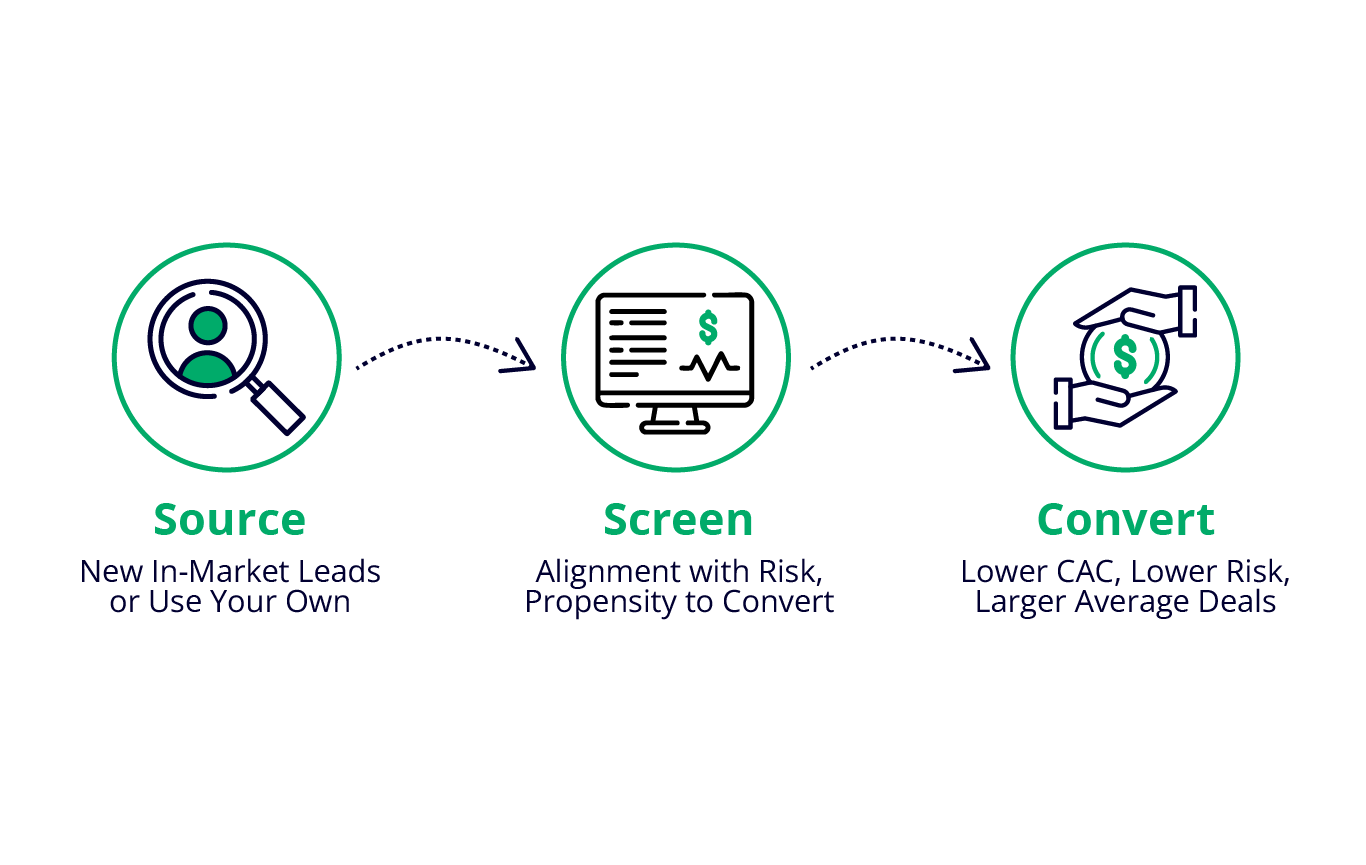
Customer Acquisition
Reach your ideal borrowers with targeted campaigns powered by our AI — designed to boost acquisition and conversion based on your specific underwriting criteria. Stop paying for leads you can't close.
Risk Strategy
Transform your risk framework into a competitive edge with our decisioning platform and expert recommendations. Grow approval volume confidently while staying ahead of evolving credit risk dynamics.
Rating Agency 2.0™
Securitize with intelligence using our advanced re-underwriting capabilities. Gain a clearer view of credit quality to make informed buying and selling decisions — minimizing risk at the portfolio level.
Trusted by Industry Leaders
Real results, real lenders, real letters on company letterhead.
I can't say enough about this company's innovation, professionalism, and speed of execution. They are disrupting the credit scoring and loan decisioning industry and it's about time.

Working with Trust Science, we have been able to support and enhance our legacy workflow, knockout rules, and business/strategy stipulations with high ROI.

Today, we rely on Trust Science in every application we look at. The T°Score™ underpins our decisions.
Trust Science and its Credit Bureau+™ service exceeded my expectations and continues to do so. The service properly and accurately scores consumers who are very hard to score.

Common Questions
Everything lenders ask before their first demo.
Approve more borrowers.
Without increasing risk.
From real-time credit insights to AI-powered scoring, Trust Science gives lenders the tools to make smarter, faster, and safer lending decisions — and find the borrowers others miss.










%20(1).png?width=200&height=85&name=logo%20(1)%20(1).png)
%20(3).png?width=200&height=85&name=logo%20(1)%20(3).png)



.png?width=200&height=85&name=Group%2031%20(1).png)
%20(4).png?width=200&height=85&name=logo%20(1)%20(4).png)
.png?width=200&height=85&name=Group%2031%20(2).png)



.gif?width=1080&height=1080&name=Untitled%20design%20(2).gif "Untitled design (2)")

Start Approving More Borrowers, Without Increasing Risk
From powerful credit insights to real-time risk assessment tools, our products are designed to help lenders make smarter, faster, and safer lending decisions. Approve more borrowers with confidence, streamline your processes, and safeguard your portfolio with Trust Science by your side.

